Spatial Analysis
Vector Relational Data Models
The applications of GIS that we have looked at so far use Feature Classes to represent actual things like streams and ponds and roads and parks. If you have gone through the introductory tutorial on GIS you know that a Feature Class is actually a table that represents each thing as a row, and a row can are made of collections of fields having a variety of potential data types including: Character Strings, Numbers, Dates, and Geometric types like Points Lines and Polygons. Applications that use data to represent real world things are known as Data Models, as illustrated in the red box in the diagram below.
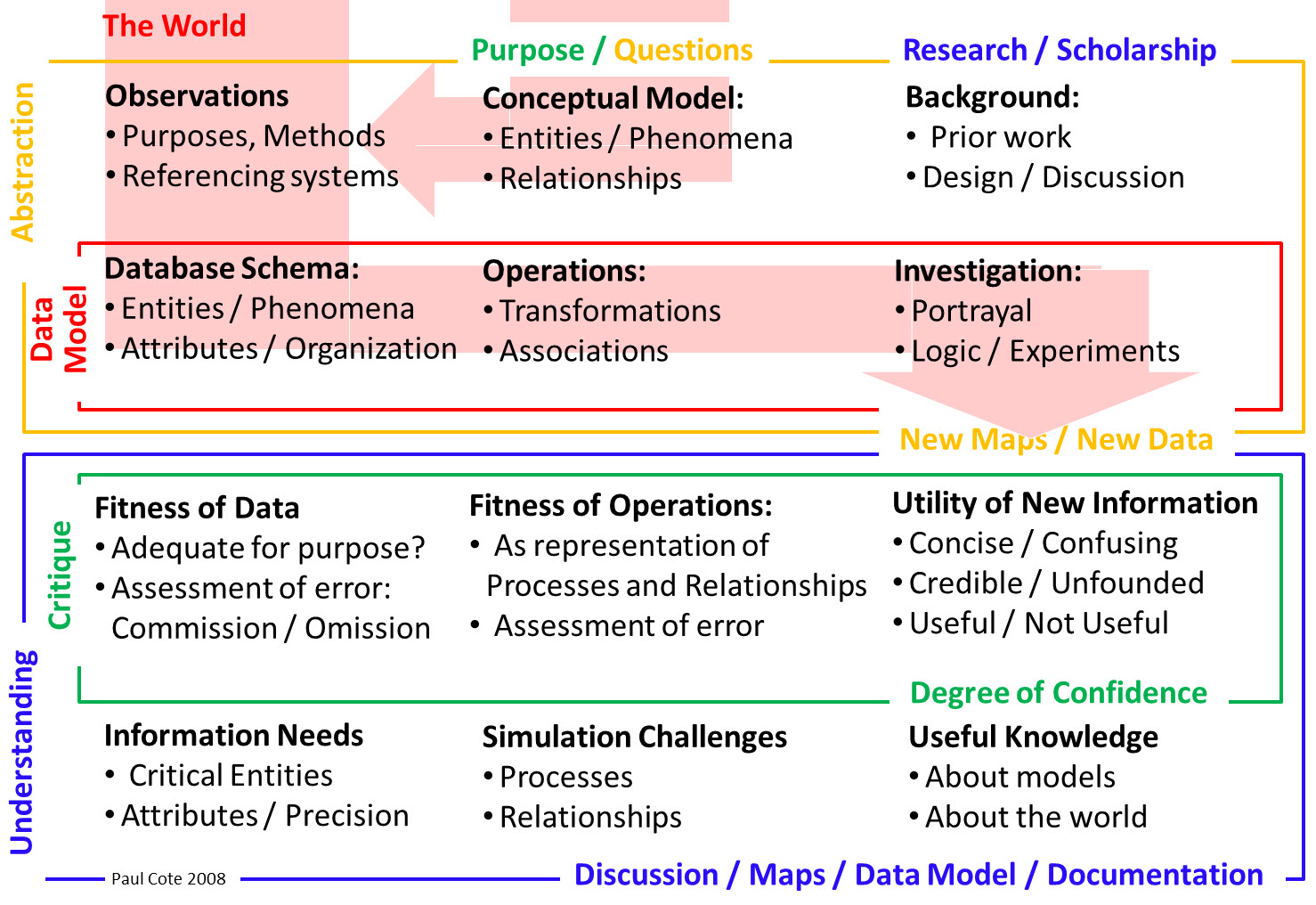
Data Models
A fundamental principle of geographic information systems is that we can use data to represent things and relationships in the real world. We do this by representing things with data and we have tools for transforming data and for exploring associations (the way things that may be represented in different datasets may be related to each other). There are two major types of data model used in GIS applications. The first is Vector Relational Databases, and the second are Raster models. These data models come with toolkits that are effectively languages that take the nouns in data and combine them with transformational and associative verbs and let us develop and evaluate logical statements about the way tings are. These languages are not software specific.
Like spreadsheet applications from different vendors use the same mathematical functions, all GIS tools including ArcMap make use of the same common languages of Relational and Raster functions. In fact, the core idea behind GIS feature classes, is a data model that is shared by practically every database management tool in use today. It makes sense, then to take a step back from ArcGIS to take a look at this language for data modeling. Taking a conceptual and historical perspective wil lhelp us to understand the problems that this language has adapted to solve and the ways that this toolkit is evolving and being extended today.
References
- Spatial Models in Scholarship and Decision Support
- Understanding GIS Data
- Data Formats for Geography
- Working with Tables in ArcMap
Introduction to Relational Database Theory and Applications
One of the greatest reasons for computers and their application is to automate tedious and repetitive tasks. This is something that the very first computers were designed for, and something that humanity continues to get better at over time. One of the most interesting stories in this history is that of the Theory and Applications of Relational Database Management Systems.
In the beginning of automated computing there were adding machines that allowed people to automate fundamental arithmetic operations. Then people developed procedures. Procedures are a means of taking simplistic operations and chaining them together in ways that will produce logical, predictable results -- for example, multiplication. Over the years ways of chaining procedures and organizing inputs have become more elaborate and more versatile.
In the 1960s, computers had made their way into many critical business applications, such as banking. In the early days of business computing each application was built from frm very low level operations. Data structures and procedures used by a particular business were intensely customized. This was good job security for programmers, but really terribly expensive and frustrating for management. By the late Sixties, some conventions had taken hold for organizing data, and for processing it. These conventions were fostered and developed by professional organizations of computer scientists. One of the important families of procedures at this time was called COBOL (Common Business Oriented Language). To build and to use a COBOL database required a lot of special programs to be written for each task.
In the late 1960s, Edgar Codd a computer scientist at IBM used the principles of set theory to describe some common patterns that most business computing applications had in common. Codd developed a set of principles for organizing data as tables and a set pf procedures for relating tables together and for extracting information from these tables. Codd's schema for Relational Database Management Systems (RDBMS), turned out to be a very versatile container for observations.
A very useful aspect of RDBMS, is that if your data are organized according to Codd's principles, then you may have a complex of many tables that form a single model of a system that can be explored through a standard, off the shelf, kit of tools, SQL (Structured Query Language.) Relational Database Management Systems (RDBMS) have become the foundation of almost all database management systems in use today. The fundamental data types and operations expected to be supported by a relational database management system are international standards enshrined by the International Standards Organization, which means that an institution can choose one vendor to supply an RDBMS and to write applications using SQL, without being worrying about whether they will be able to fire that vendor and move their information assets to another system. The Vector GIS feature classes (like shapefiles) and the handy functionality of Lookup Tables and Joins that we have been using over the past few weeks are based on this fundamental means of organizing information. For more detail on the history of database management systems see the Wikipedia Article on Database Management Systems.
Principles of Relational Schema and Structured Query Language
A very important aspect of relational database systems is that the powerful set of tools that they give us for extracting new information from associations of tables depend on some premises about how information about entities is broken down into table rows and attribute fields.
Real-World Entities are represented as collections of attributes. If we have a set of featuers that are considered to be the same class of thing (e.g. property parcels) then each thing can be represented by a row in a table where the values for the parcel attributes (e.g. Parcel_Owner, Parcel_Area, Parcel_Land_use) can all be stored as the fields or columns in the table.
In the classic form of relational databases, the values of attributes could be represented with four basic data types:
- Character Stings
- Integer Numbers
- Decimal Numbers
- Dates
Codd's SQL had several ways of creating associations between rows in a table. These basic associtive operations include:
- Sorts (order the parcels by land area)
- Filters (Select parcels having a land use of Industrial and an area grater than 5 hectares.)
- Summaries (Sum the land area of the set of industrial parcels.)
As we said earlier, Codd stipulated that there are principles for organizing tables if we want to use them with SQL.
- Each thing should be represented by a single table row. (otherwise we may double count things.)
- The attributes or data fields recorded in the data fields for each table row must be attributes of the things themselves. So for example, recording the Owner_Income in the parcels table is another condition that could result in double counting (among other problems.)
- The information in each field should be atomic -- that is, it is a bad idea to use a field to hold more than one piece of information. A common violation of this is the se of one field to hold City, State and Zipcode.
Codd's rules are known as the Normal Forms. It is quite common to find examples of tables that violate these rules and everyone should be aware that when this is the case, we may continue to use SQL, but the summaries that are returned by SQL may be incorrect.
Table Joins
The associative functions described above are ways of learning new things from individual tables. But Relational Databases and SQL also allow us to represent relationships between different types of things which would be represented in different tables. For tables organized according to certain principles we can create SQL queries that span multiple tables. For example: how many property parcels from the parcels table are owned by Owners from the Owners Table where the Owners income is greater than $100,000 and the Owners_Address ZipCode city? Queries that span multiple tables are known as Joins.
The key requirements of tables involved with joins include the two rules above with an additional one:
- The Owners Table must have have one field which that is a unique identifier (key) for owners.
- The Property_Parcels Table must have a field that references the appropriate row from the Owners Table with a reference with this unique key. This reference is known as the Foreign Key.
Normalization
Like most powerful tools, to use SQL effectively, one must be aware of the requirements of the normal forms and should be careful to see that these principles are upheld by the tables that they are using. The process of fixing table so that they conform to the principles is known as Normalization. It is possible to use SQL happily without understanding this, The problem with doing so is that the "answers" returned by your queries are likely not to be correct. There is also the danger that costly time and effort may be spent to put information into tables that cannot be accessed with common SQL.
Table Views
One property of relational data models that makes it so versatile is that while tables are filtered or transformed and associations are created with SQL queries, the result is always a new table. And this makes it natural to chain procedures together to create very elaborate models that will run with minimal supervision. Usually, the tables that result from a query are not actually saved to disk unless explicitly directed to do so. These intermediate tables are known as Table Views. In ArcMap, you can see this behavior if you use Definition Queries and Joins.
SQL is a Stable International Standard and a Free Software Commodity
One of the great things about relational Databases and SQL is that, as a set of rules for organizing and accessing data, RDBMS and SQL are completely in the public domain. In fact, SQL is an international standard managed by the International Standards Organization. There are many commercial, proprietary software products that provide RDBMS and SQL capability -- like Oracle, Microsoft Access, and SAS. There are also many open-source, community developed RDBMS tools like MySQL and Postgres. Because of the standard expactations for SQL and RDBMS these tools are essentially interchangeable. When it comes to very large data operations and security requirements, there are important considerations that may make an organization to pay big money for a flagship commercial system.
Relational Databases Extended to Geographic Data Types and Relationships
In today's language, SQL provides an application programmer's interface (API) for potentially very large databases. This makes it easy to embed SQL into programming applications and also to embed custom cored into relational databses. This versatility is often used to create custom data types and custom procedures that represent new sorts of relationships. For example, creating a two dimensional data type that represents a point introduces a potential to have a new logical operator called Distance. With this we could select the points having distance to some location less than 50 meters. Long story short, a not-for-profit consortium of interested parties (The Open Geospatial Consortium) has defined a set of spatial extensions to the SQL standard. The SQL Extensions for Simple Features (Points, Lines and Polygons) includes scores of new spatial operators that deal with practically every sort of two-dimensional relationship that you can imagine. Because this language is now governed by the International Standards Organization (ISO), it is a stable, non-proprietary language that we can all use to exchange very clear, actionable information about how we arrive at our analytical conclusions.
An organization of tables that are designed to work together to model a system is known as a Schema. The General Transit Feed (GTF)is a good example of a schema. The GTF is the way that transit systems publish their routes, stops and time tables to participate in networked transit models such as Google Maps.
The ESRI Geodatabase is a particularly intersting example of the Relational model being extended. Thjis article, The Geodatabase: Modeling and Managing Spatial Data form the 2009 issue of ArcNews provides a good overview of how the ESRI Geodatabase adds data types that model specific types of features and relationship including property parcels and subdivisions, utility and transportation networks and generalized cartographic representations.
Another interesting recent development in our ability to encode and exchange relational databases is new standard formats for encapsulating collections of tables with prescribed relationships (schema) as a single binary file. The Open Geospatial Consortioum Geo Package is one such open standard for exchanging schema.
Parting Thoughts
Observers of nature have learned that many species have ways of learning about their environment and for passing useful references from one individual to another. From ants, to turtles to birds and bees, these ways of collective research and societal learning are essential to the survival of the species. Although we are still struggling to understand how other species are able to do this. We can say that vector relational databases have become an important means that human beings have for building a societal understanding of our world.
